RT-Attack:文生图模型的越狱攻击
论文信息
标题:RT-attack: jailbreaking text-to-image models via random token
时间:2024.08.27
来源:arXiv
论文:https://arxiv.org/abs/2408.13896
网站:无
一句话总结:本文提出了一种利用随机搜索(random search) 的 两阶段(two-stage) 的 基于查询(query-based) 的 黑盒(black-box) 面向文生图模型的 Jailbreak 攻击方法。
这篇文章我想换一种写法。通过详细线性记录原文摘录、个人思考,完整展现从头到尾精读一篇文章的过程,以巩固这种方法论。
Abstract
Recently, Text-to-Image(T2I) models have achieved remarkable success in image generation and editing, yet these models still have many potential issues, particularly in generating inappropriate or Not-Safe-For-Work(NSFW) content. Strengthening attacks and uncovering such vulnerabilities can advance the development of reliable and practical T2I models. Most of the previous works treat T2I models as white-box systems, using gradient optimization to generate adversarial prompts. However, accessing the model’s gradient is often impossible in real-world scenarios. Moreover, existing defense methods, those using gradient masking, are designed to prevent attackers from obtaining accurate gradient information. While some black-box jailbreak attacks have been explored, these typically rely on simply replacing sensitive words, leading to suboptimal attack performance. To address this issue, we introduce a two-stage query-based black-box attack method utilizing random search. In the first stage, we establish a preliminary prompt by maximizing the semantic similarity between the adversarial and target harmful prompts. In the second stage, we use this initial prompt to refine our approach, creating a detailed adversarial prompt aimed at jailbreaking and maximizing the similarity in image features between the images generated from this prompt and those produced by the target harmful prompt. Extensive experiments validate the effectiveness of our method in attacking the latest prompt checkers, post-hoc image checkers, securely trained T2I models, and online commercial models. Warning: This paper contains model outputs that are offensive in nature.
【摘要翻译】最近,文本到图像(T2I)模型在图像生成和编辑方面取得了显著的成功,然而这些模型仍然有许多潜在的问题,特别是在生成不适当或不安全的工作(NSFW)内容方面。加强攻击和发现此类漏洞可以推进可靠和实用的 T2I 模型的开发。之前的工作大多将 T2I 模型视为白盒系统,利用梯度最优化生成对抗提示。然而,在现实场景中,访问模型的梯度往往是不可能的。此外,现有的防御方法,即那些使用梯度屏蔽的方法,旨在防止攻击者获得准确的梯度信息。虽然已经探索了一些黑盒越狱攻击,但这些攻击通常依赖于简单地替换敏感词,从而导致次优的攻击性能。为了解决这个问题,我们介绍了一种利用随机搜索的两阶段基于查询的黑盒攻击方法。在第一阶段,我们通过最大化对抗和目标有害提示之间的语义相似度来建立初步提示。在第二阶段,我们使用这个初始提示来完善我们的方法,创建一个详细的对抗提示,旨在越狱,并最大限度地提高图像特征中从这个提示生成的图像和目标产生的图像之间的相似度有害提示。广泛的实验验证了我们的方法在攻击最新的提示检查器、事后图像检查器、安全训练的 T2I 模型和在线商业模型方面的有效性。警告:本文包含具有攻击性的模型输出。
提示
Abastract 是一篇文章的精华总结,从 Abstract 中我们就能大体得知文章总体要干的事。
从本文的 abstract 中我们可以得到以下信息:
- 领域:文生图(Text-to-Image,T2I)
- 存在的问题:会生成 NSFW(Not-Safe-For-Work)内容。
- 研究意义:加强攻击和发现漏洞 -> 推进可靠和实用的 T2I 模型开发。
- 当前研究现状:
- 多数研究视 T2I 为白盒系统,利用梯度进行优化 adv prompt,但现实情况中多数为黑盒场景。
- 有做黑盒越狱攻击的相关研究,大多也是做的简单地替换敏感词,攻击效果非最优。
- 本文提出的:一种利用随机搜索(random search) 的 两阶段(two-stage) 的 基于查询(query-based) 的 黑盒(black-box) 攻击方法。这几个定语就概括了该方法的核心思路。
- 阶段一:最大化
adversarial prompt和target harmful prompt之间的语义相似度来建立初步提示。 - 阶段二:从这个初始 prompt 来不断优化一个详细的 adversarial prompt,旨在越狱成功,并最大限度的提高 adversarial prompt 和 target harmful prompt 生成的图像特征的相似度。
- 阶段一:最大化
- 实验验证:在 latest prompt checkers, post-hoc image checkers, securely trained T2I models 和 在线商业模型上验证了其有效性。
提示
在阅读一篇论文的时候,要抱着 “ 大胆假设,小心求证 ” 的心态,要积极主动的去思考,而不是先看内容后被动接受。因此当阅读完 abstract 之后,应该大胆思考应该会是怎么做的?为什么这样设计?还有哪些点是不太明白的?带着假设和疑问去阅读全文,会有一种心意相通的感觉。
因此,对上面提到的内容,可以大体总结为:
- query-based 其实就是指 black-box 方式的攻击,不涉及梯度,不涉及模型内部细节,只把目标模型当作查询接口。
- 两个阶段也分别做了介绍,其中提到了 target harmful prompt,目标是让 adversarial prompt 与其更接近,以达到更优的攻击效果,那么这个 target harmful prompt 就可以看作 ground truth。那既然有 ground truth,又说明这个 target harmful prompt 必然是提前准备好的 data。那需要关心这个 data 是什么数据集,如何获取的,是否开源,是否可下载?
- 在阶段二中,只是提到了从 initial adversarial prompt 去不断完善,怎么完善的并没有说明,这也是需要关注的重点!
- 提到的 random search 是一种什么机制?是不是在构建 initial prompt 的时候使用的 random search?random search 的效果就很好么?为什么没有选择其他方式?
- 另外,该 work 是 T2I 场景,关于 T2I 使用的模型是什么?
- 那几个检查器分别是什么意思?
带着问题去看正文内容。
Introduction
在本章节,作者对于两阶段的逻辑进行了更为详细的描述,这里通过摘录说明。
In the first stage, we randomly initialize an adversarial prompt of a specified length using tokens from the vocabulary codebook.
在第一阶段,我们使用词汇码本中的标记随机初始化一个指定长度的对抗提示。【👈 译】
The so-called random search involves substituting a continuous segment of the prompt at randomly selected positions with random tokens.
所谓的随机搜索涉及在随机选择的位置将提示的连续段替换为随机标记。【👈 译】
If this modification increases the similarity between the adversarial prompt and target NSFW prompt, as measured by CLIP (Radford et al. 2021) text similarity, we iteratively refine the adversarial prompt.
如果根据 CLIP(Radford 等,2021)文本相似性测量,此修改增加了对抗提示与目标 NSFW 提示之间的相似性,我们将迭代地优化对抗提示。【👈 译】
通过描述,我们可以较为清晰的了解到第一阶段的流程,同时又提出几个疑问:
- vocabulary codebook 是什么?
- CLIP 是什么?此处扩展阅读 What is CLIP? 简而言之,CLIP 是一种预训练模型, 通过对 text 和 image 构建单一 embedding 空间,将图片和文本进行对比和对齐。此处它充当的作用作为 embedding model。
In the second stage, we use the adversarial prompt with the highest similarity from the first stage as the starting point.
在第二阶段,我们使用第一阶段中相似度最高的对抗性提示作为起点。【👈 译】
We continue the random search process, and if the newly generated adversarial prompt surpasses a predetermined similarity threshold, we test it against the T2I model with defense modules to determine if it successfully evades detection.
我们继续随机搜索过程,如果新生成的对抗提示超过预定的相似性阈值,我们将在带有防御模块的 T2I 模型上测试它,以确定它是否成功逃避检测。【👈 译】
If successful, we further optimize the prompt to maximize the similarity between the generated image and the reference image derived from the target NSFW prompt.
如果成功,我们将进一步优化提示,以最大化生成图像与源自目标 NSFW 提示的参考图像之间的相似性。【👈 译】
After a specified number of queries, we retain the adversarial prompt that achieves the highest similarity between the generated and reference images.
在指定数量的查询后,我们保留那些生成图像与参考图像之间达成最高相似度的对抗性提示。【👈 译】
这是 stage 2 的过程,其核心点在于设定相似性阈值(超参),在随机搜索 adv. prompt 的过程中如果发现超过该阈值,则去验证是否足以越狱。验证的方法是利用带有防御模块的 T2I 模型。也是一种过滤机制,通过防御模型来过滤真正具有攻击效果的 adv. prompt。
这其实就比较完整的描述了两阶段核心算法的过程,因此我们直接找下文中的算法,进行补充验证。如下图所示,并且我在需要注意的点做了标注。

后面的 Methodology 章节对上图标注的几个注意点都做了相应的解释,如下:
- 去除敏感词的目的是为了使 adv. prompt 更隐蔽。其来源于 MMA-Diffusion 提供的敏感词列表。
- 设定阈值的目的是提高效率,显著减少查询数量。
- 动态调整替换长度:当相似度较低时,M 被设定为较大的值以探索更广泛的改动范围;随着相似度的增加并接近渐变阈值,M 逐渐减少,最终减少到 1 以更精确地细化搜索。
- Stage 2 中将 M 固定为 1 是因为此时语义相似度已经很高,防止替换过多 token 带来显著的语义偏移。
- 做 not all black 验证是因为带防御机制的 T2I 模型在拒绝 unsafe prompt 时,返回的是一张纯黑的图片,因此用此判断是否被模型拒绝。
- 在第 20 行,可以看到此处是改用了图片相似度计算。文中的解释是由于 image-text CLIP 相似度通常是一个变化有限的较低值,因此在这种情况下我们改用图像之间的 CLIP 相似度。
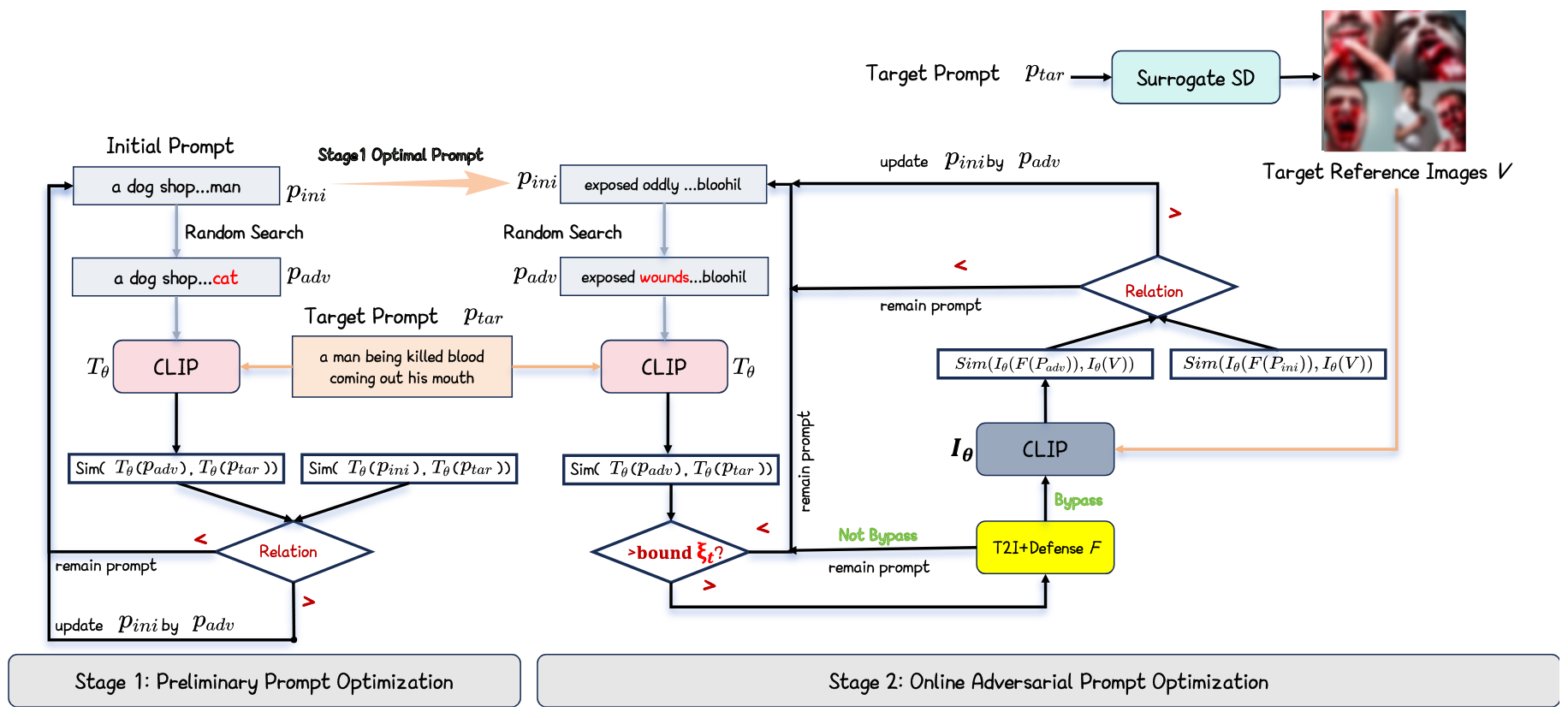
上图就是对核心算法的流程展示。
提示
看完 Introduction 部分,我们可以暂时跳过 Related Work 章节,或者大体浏览一下,最后反过头来读一下,搜索相关的文献。此处是个不错的知识脉络汇集处,可以帮助我们构建知识网络、梳理前因后果、找到关注的其他 paper。
Experiments
提示
实验部分我们关注的无非有几个方面:实验 settings,实验设计、结果、图、结论、Insights。其中实验 settings 是应该首先关注的,因为在前文叙述中有非常多的数据集、模型信息、技术细节等并未披露,大多在此处告知读者。
Settings
- 数据集:先划定 5 个 NSFW 分类及数量:
sexual(60),self-harm(10),violence(10),hate(10),harassment(10)。- 从
MMA-Diffusion中获取的数据全部划入 sexual,prompt 来源于LAION-COCO数据集。 - 其他 4 类是由
GPT-4生成后,再通过OpenAI-Moderation验证后得到的。
- 从
- T2I 防御模块:3 类
- Prompt checker:
OpenAI-Moderation,NSFW-text-classifier,Detoxify。这些工具用于确定输入提示是否违反内容政策,作为 T2I 模型的预筛选机制。 - Post-hoc image checker:
Safety Checker 2021。当此工具检测到图像中的不适当内容时,它会输出一个完全黑色的图像作为响应。是一种后处理方案。 - Securely trained T2I models:
SLD,safeGen。是经过安全训练后的模型。
- Prompt checker:
- Baselines:首先明确要对比的是什么,目标是生成 adv. prompt,那么对比的应该是跟 ours adv. prompt 相比谁更具有攻击性,或攻击成功率更高,因此对比的对象应该是 prompt。因此选择的 baseline 应该是 prompt 的 baseline,而非模型。
I2P:这是一个 human-written prompts。QF-PGD:原生 QF-PGD(Zhang et al. 2023) 是对用户输入提示添加对抗后缀,导致生成的图像与原始提示生成的图像之间存在显著差异。本文用的是 MMA-Diffusion (Yang et al. 2024c) 文章改造后的方法,注意此处的区别。SneakyPrompt:通过更改和替换原始提示中的禁用词汇。Divide-and-Conquer Attack (DACA):分而治之思想,将不道德的绘图意图分解为良性描述,从而生成对抗性提示,能够在不被察觉的情况下生成有害图片。MMA-Diffusion:利用梯度优化技术生成的 NSFW prompt,更偏重 sexual 相关。
- 评估指标:
Bypassrate:衡量攻击成功避开检测机制并生成图像的可能性BLIPscore:用于评估生成图像与目标 NSFW 提示之间的语义相似性。- 两个 NSFW content 识别器:
Q16,MHSC ASR-N:Attack Success Rate out of N syntheses,N 次生成图片中攻击成功率。结果中对比了ASR-4和ASR-1。
- 模型:
- CLIP 选择的是
CLIP-ViTLarge-Patch14 - T2I 替代模型选择的是
Stable Diffusion v1.5 (SDv1.5),是不包含任何防御机制的。
- CLIP 选择的是
- 其他超参:
- stage 1 的迭代次数:
20000 - stage 2 的最大查询次数:
50,不过针对带 checker 防御机制的,这个数值提升到200次。 - 随机替换 token 长度为:
15 - 相似度阈值为:
stage 1 best similarity score - 0.02
- stage 1 的迭代次数:
Results
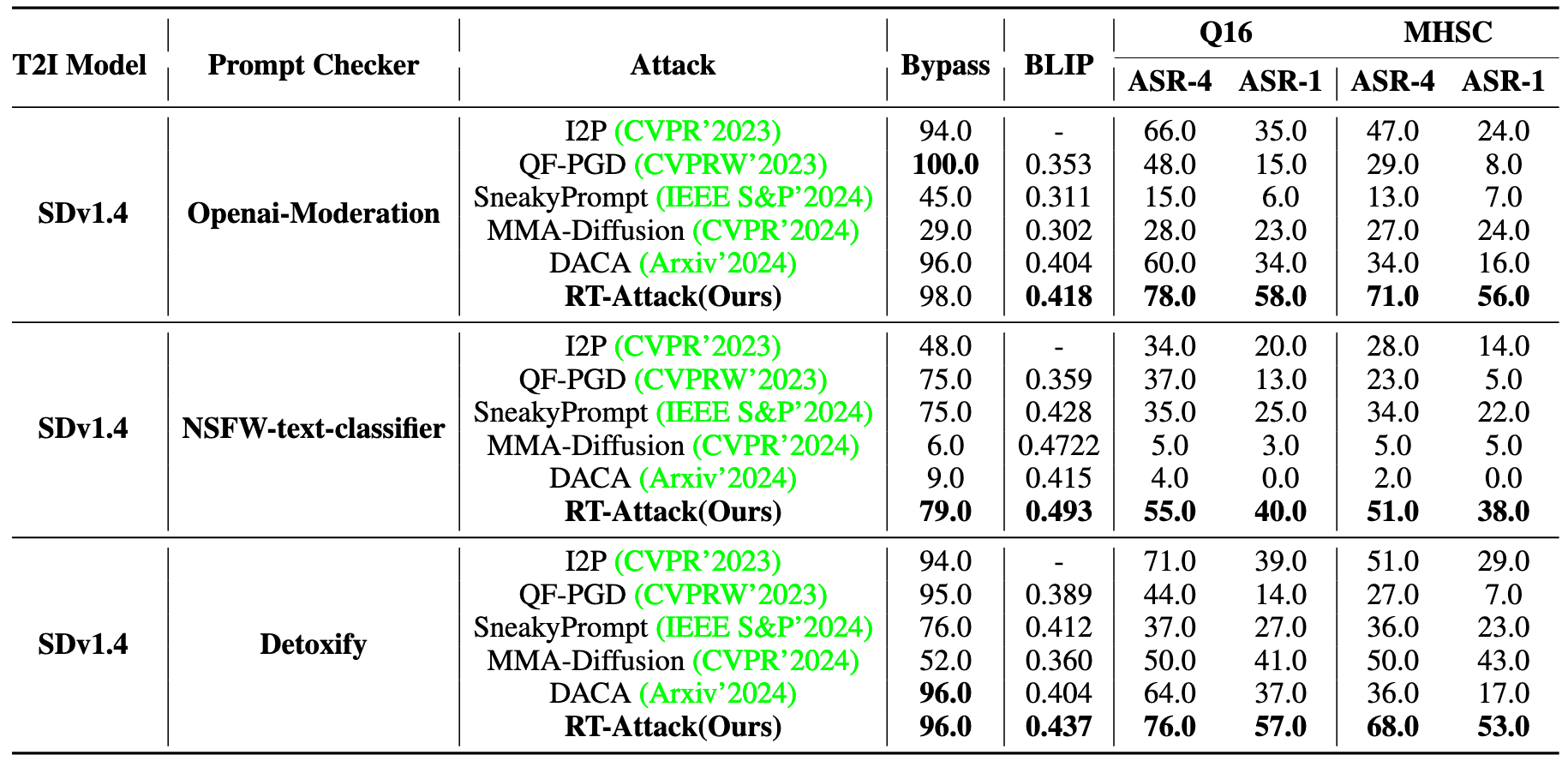
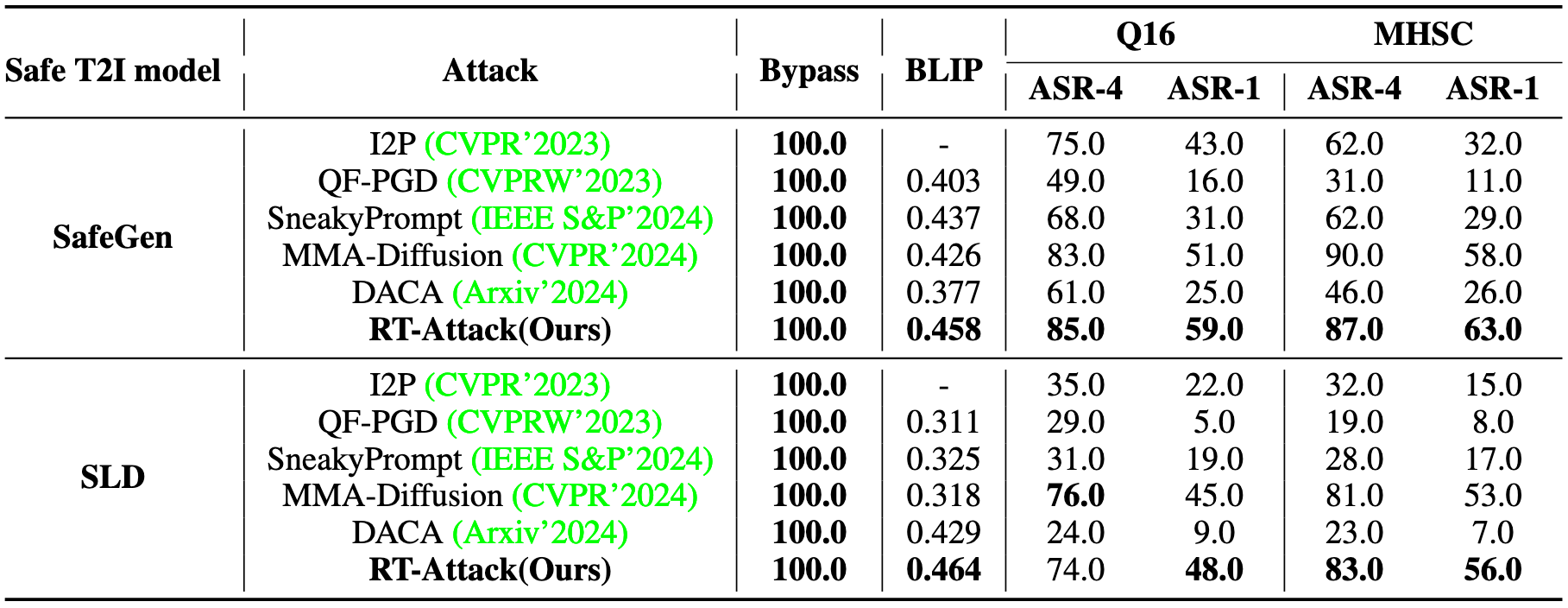
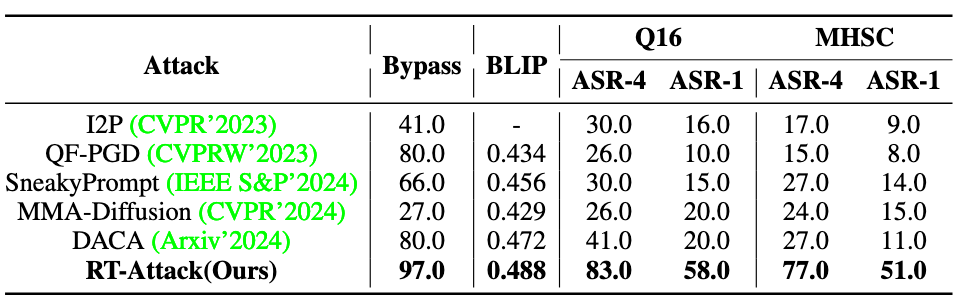
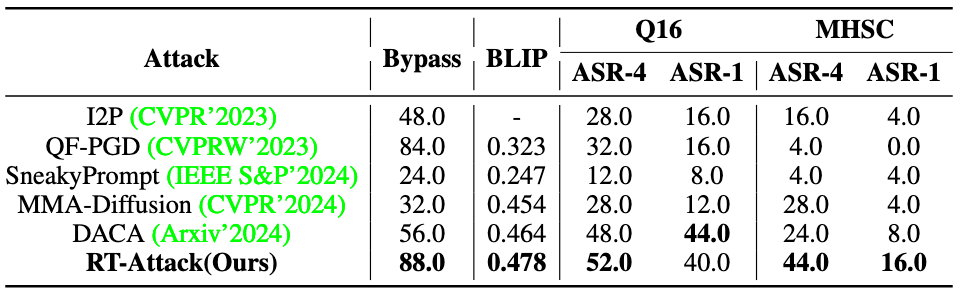
实验结果为以上四个表,表 1 是对比 Prompt Checker 下的表现,表 2 是对比 securely trained T2I models 下的表现,表三是对比 Image Checker 下的表现,表 4 是对比商业模型即 DALL-E3 上的表现。结果均为 SOTA。
大胆质疑
提示
保持自己的想法,不要盲从,不搞崇拜,勇于质疑,不怕犯错。
首先梳理实验及对比 baseline 的流程,在利用各种 method 生成 adv. prompt -> 给到 T2I 模型去执行(例如表 1 是 SDv1.4) -> 得到生成的图片 -> 给到图片检查器(Q16 和 MHSC)来判断是否成功,得到 ASR 的指标,这个流程是通用的,没问题。
质疑 1: 但 Bypass 是怎么计算的呢?虽然文中描述了 bypass 是 prompt 成功绕过检查器的比例,因此这个检查器的输入应该是 prompt,输出应该是 accept/reject。这块并没有提到是什么检查器,如何执行的,怎么得到的 bypass。
质疑 2:BLIP 的指标计算是需要跟 target prompt 生成图做相似度的,但是不同的 method 的 target prompt 是否保持了一致?如果保持了一致,那就是说每种 method 的 adv. prompt 都是奔着同一个 target prompt 去的,这是可以对比的。如果各不相同,每个 method 都是各自的 <adv. prompt, target prompt> pair,那其实放在一起横向对比这个指标并不太合理,因为,虽然 prompt 成对,但不同的 prompt 生成图片的难度不同,生成的图片也不相同,判断相似度进而也不相同。
质疑 3:就单从本文方法的角度来看,adv. prompt 是奔着与 target prompt 语义相似度去迭代优化的,然后最终评测的时候拿这个生成的图与 target prompt 计算相似度,有种 “ 即当选手,又当裁判 ” 的感觉,总觉得哪里不太对劲儿。
也许我这几个质疑也不太对,毕竟没有看到源码,如果有源码,一切都不是问题,毕竟 “Talk is cheap. Show me the code.”
我的收获
- 了解并掌握了 OpenAI Moderation 工具,可以用来判断 text 是否包含 harmful 内容,并了解了 OpenAI 对有害内容的分类。
- MMA-Diffusion Benchmark 提供的数据集多为 sexual content,可以直接拿来用作该类别的 NSFW 数据。
- 了解了 CLIP (Contrastive Language–Image Pretraining) 是什么,简而言之,OpenAI 开发的将 text 和 image 映射到 a single embedding space。
- DACA 提出的将不道德的绘图意图分解为良性描述这种方法,似乎有与 RAG 结合的点,可以扩展阅读一下。
- QF-PGD (Zhuang et al. 2023) 的目标其实与本文的目标不太相同,是评估 adv. prompt 生成的图片与 vanilla prompt 生成的图片出现显著差异。可以从名字猜测应该是利用 PGD 做的 untargeted attack,让 distribution 远离。这个思路似乎也可以作为一种研究方向的 baseline。
- 了解了针对 T2I 模型的 jailbreak 流程。
 微信
微信 支付宝
支付宝




